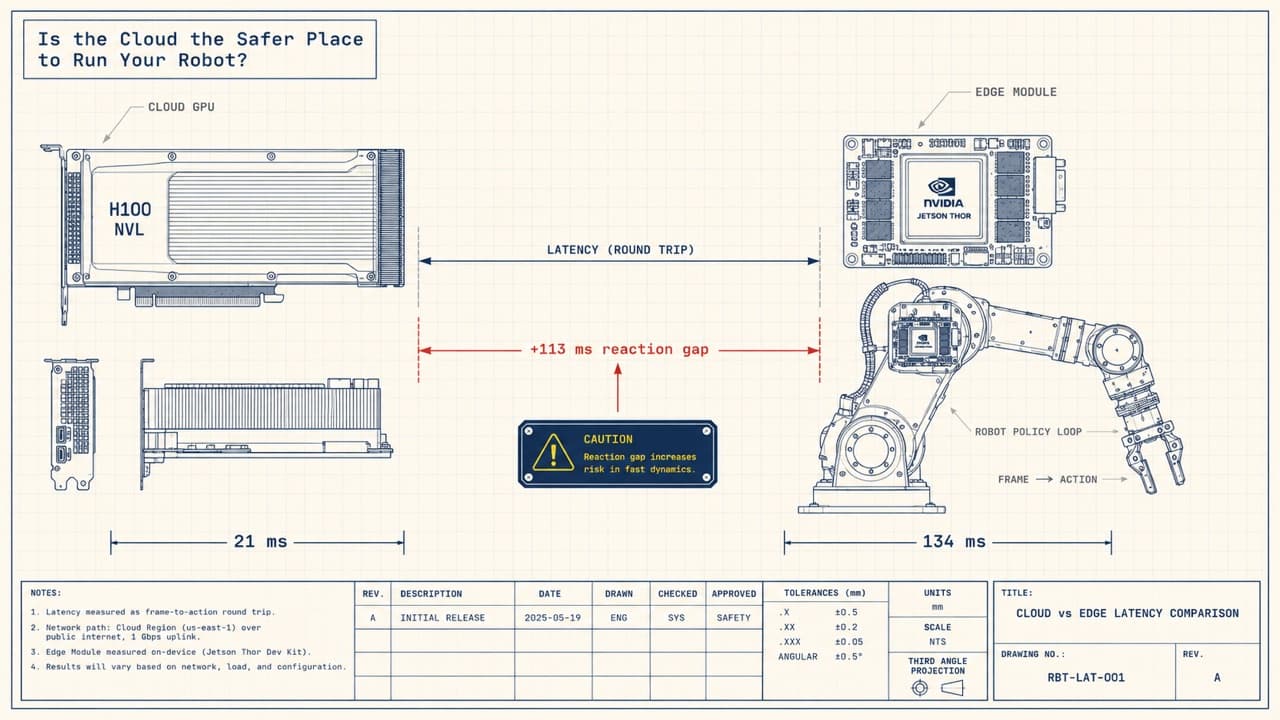
TL;DR
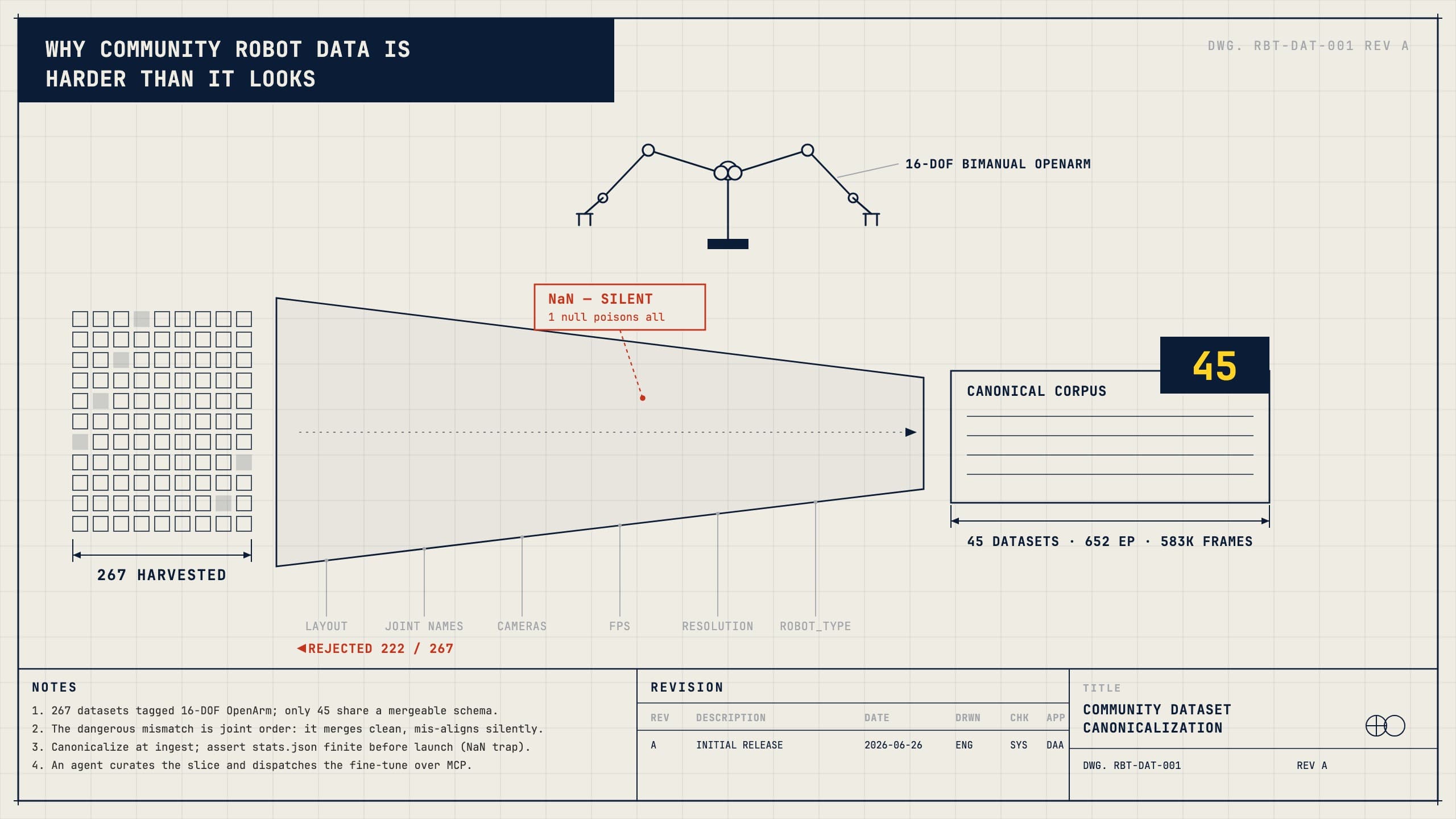
- This isn't an OpenArm problem, it's a community-data problem. We harvested 267 datasets all tagged "16-DOF OpenArm." In one merge pass, only 45 combined into a clean, trainable corpus. The "same robot" label hid four out of five.
- The trap that almost cost us a run never crashed. All 582,660 frames scanned clean, yet a single null in the statistics turned normalization to
NaNand trained a model that learned nothing, with no error to say so. - An agent drove the whole loop over MCP: it read each dataset's real schema, kept the slice that actually merges, and dispatched the fine-tune (Pi0.5, H100, loss
0.248). The layers are universal. The point is not peeling them by hand.
What we set out to do
Why we wanted one trainable OpenArm corpus out of public data, and why an agent should assemble it.
We wanted to fine-tune Pi0.5 on the OpenArm, a 16-DOF bimanual robot, using data that already exists in public. The community has been generous: hundreds of OpenArm datasets sit on the Hugging Face Hub, recorded by labs and hobbyists, all nominally the same arm doing manipulation. If the data is free, the corpus should be free too.
And we wanted an agent to own the hard part, not just press go. Our pipeline runs on Claude Code over MCP (the protocol the agent drives the platform through): it picks datasets, reads their real schemas, authors a typed run file, dispatches the fine-tune, and reads back the result. No human clicking through a form, and no human hand-merging parquet at 2am.
The premise was that the data was the easy half. It always is, right up until you try to merge it. That was the hard half.
What a "dataset" actually is
The format, and the one thing that has to line up before any of this works: the schema.
If you already live in LeRobot and know an episode from a stats.json, skip to the seven layers.
A robot dataset is a set of episodes (one recorded attempt at a task), each a sequence of frames. A frame holds the robot's action and observation.state (joint positions, one number per degree of freedom) plus one image per camera. On disk, LeRobot v3.0 keeps the frames as Parquet, the videos as MP4, and the bookkeeping in JSON, including the stats.json that holds the per-feature mins and maxes used to normalize inputs before they reach the model. Hold onto that file; it's where the trap is.
To merge two datasets you need them to agree on one schema: one joint layout, one set of joint names, one camera set, one fps, one resolution, one robot_type string. Force every dataset into that and they aggregate. The catch is that almost none of them arrive in it, and the ways they differ are not the ways you would guess.
The same robot, seven different ways
Every "16-DOF OpenArm" dataset is its own snowflake. The dangerous kind merges without complaint and silently mis-aligns the joints.
Tag two hundred datasets "the same robot" and you would expect them to merge. They don't, and the reason isn't exotic: "16-DOF OpenArm" pins the joint count and nothing else. Underneath that label the data fragments a dozen ways, and only one of them is dangerous.
The dangerous one is joint order. One dataset stores the left arm first, the next stores the right arm first, the action vectors are the same shape, so they merge without a single error and every frame is now teaching the model that the left gripper is the right elbow. Nothing crashes, but the loss goes down.
You find out when the policy moves the wrong arm.
The rest are the same story in a lower key: the joints are named three different ways, the cameras are called base or top or wrist_left, the frame rate is 15 in some and 30 in others, the resolutions don't match, the robot_type string is spelled three ways. Each is a filter, and each filter reveals the next. None of it is in the metadata.
This is where the agent earns its keep. It reads each dataset's real schema instead of trusting the label (the slug can lie; a "bimanual" tag can hold a one-arm copy), buckets the catalog by the full schema, and keeps the largest slice that actually merges. Without that, you find the heterogeneity by crashing into it. With it, the agent finds it first. And the OpenArm is not special here: harvest any robot's community data and you get the same snowflake.
The merge that trains nothing
One null, buried in the statistics, that trains a model on nothing and never tells you.
The seven layers fail loudly. This one fails in silence, and is what became the biggest time sink for us.
We merged a clean set, launched the fine-tune, and watched loss: nan from the first logged step. It happened right away (not after an hour). Eight GPUs pinned and the run was "training," but the checkpoint was quietly filling with garbage. A run that cost us real money and produced nothing, with no error to tell us so.
The strange part: every one of the 582,660 frames was finite. The poison was upstream, in the statistics. The merge computes the normalization from each episode's pre-computed stats, not from the frames, and one episode had a single null in there, a near-constant joint whose value came out empty. That one null spread to NaN across every dimension of the normalizer, the model divided every action by NaN, and the loss was nan before it ever saw a real frame.
The fix is three lines of discipline: 1) sanitize before you aggregate, 2) recompute the stats from the clean frames, and 3) refuse to launch on a stats.json that isn't finite. Those three checks belong in the merge pipeline vs in your memory. We paid for them once so the next run never sees the nan.
What survived
The honest accounting, which is the number the agent hands you.
Heterogeneity significantly shrinks the usable set. Of the 267 datasets tagged 16-DOF OpenArm, 45 merged cleanly: 652 episodes, 583k frames. Four out of five didn't survive contact with a real schema.
It trained
A first Pi0.5 fine-tune on the OpenArm, curated and dispatched end to end by the agent.
The 45-dataset corpus fine-tuned Pi0.5 to completion on an H100: loss 0.248, a loadable checkpoint.
The biggest success was that no human opened a training script. The same agent that curated the corpus and caught the traps authored the run: it called create_run to pick the policy, the embodiment, and the data, then write_run_file to write a typed, version-pinned recipe, and the platform dispatched it on the compute host. The embodiment resolved from an id, the cameras wired to the right streams, the base model pulled from our own mirror instead of depending on Hugging Face mid-train.
One corpus, four model families
Why you store the data once but can't pre-shrink it, and why camera count is a hard gate.
We don't want this corpus to feed only Pi0.5. We want it to fine-tune SmolVLA, MolmoAct, and GR00T too, and that constrains exactly one decision: how big you store the images.
Each family wants a different input size and resizes inside its own preprocessor, so you can't pre-shrink to one of them. Pi0.5 wants 224 pixels; MolmoAct tiles, and exploits source images as large as you can give it. Store at 224 to please Pi0.5 and you've permanently capped MolmoAct at a resolution it was built to beat. So you store the frames at the highest resolution you have and let each model downsample at load.
Camera count is the one rule that isn't a preference, it's a gate. SmolVLA is wired for exactly two cameras; a three-camera OpenArm rig (head plus two wrists) won't load into it without changing the model. Pi0.5, MolmoAct, and GR00T take a variable count. So "how many cameras" is a question you answer before you pick a family, not a knob you turn after. (LeRobot 0.5 doesn't yet train on native-resolution multi-dataset corpora the right way; building that path is on us, and in progress.)
| Model | Input size | Cameras |
|---|---|---|
| Pi0.5 | 224 px | any count |
| SmolVLA | 512 px | exactly 2 |
| MolmoAct | tiles, native res | any count |
| GR00T | 224 px | any count |
Store above the highest of these and let each model downsample at load. Pick the camera count before the family.
The camera you cannot normalize away
The distribution shift no canonicalization step can fix.
Everything above you can fix by rewriting metadata and filtering frames. Joint order, names, fps, resolution, camera count, robot type: all of it canonicalizes into one schema.
You cannot canonicalize the lens.
A camera's optics and placement are part of the data distribution, not its metadata. The wrist cameras in a harvested corpus are mostly plain rectilinear lenses in a particular spot. Put a fisheye on the wrist of the robot you actually deploy, and it sees a warped, wide-angle world the training data never contained. The schema check passes and the policy still underperforms, because you trained it on one visual world and asked it to act in another. You can resize an image. You can't un-warp a fisheye back into a lens the corpus never had. The honest open question is how much that costs in task success, and whether the fix is data (record on the real optics) or model (train across enough lenses that it stops mattering). Worth measuring, not asserting. It's next on our list.
What's next
The eval we built but haven't run on a real policy, and the call.
We've built a closed-loop, task-success eval in a MuJoCo OpenArm scene, plus a system-ID check that the sim tracks the real arm. It's built and unit-tested; it hasn't been run against a real fine-tuned policy yet. That's the honest gap to close next, alongside a bigger run on the full corpus.
The seven layers, the silent NaN, and the lens problem are not OpenArm-specific. They're what community robot data looks like up close, and handling them, with an agent driving curation, canonicalization, and fine-tuning over MCP, is what we're building the Haptic platform to do.
If you're fine-tuning policies on community data, on any embodiment, and hitting the same walls, join the waitlist to get on the platform and skip rediscovering these layers by hand. We'd like to compare notes either way.
Thanks to the LeRobot team at Hugging Face for the format and the tooling, to Physical Intelligence for Pi0.5 and openpi, and to the OpenArm community and every lab and hobbyist who uploaded a dataset. None of this exists without data you chose to make public. And a special thanks to the team at Addition, whose work got us thinking hard about all of this in the first place.