TL;DR
- The “Hugging Face for robotics” is a meme in robotics circles. LeRobot is great, but people want more, so we go into what is missing.
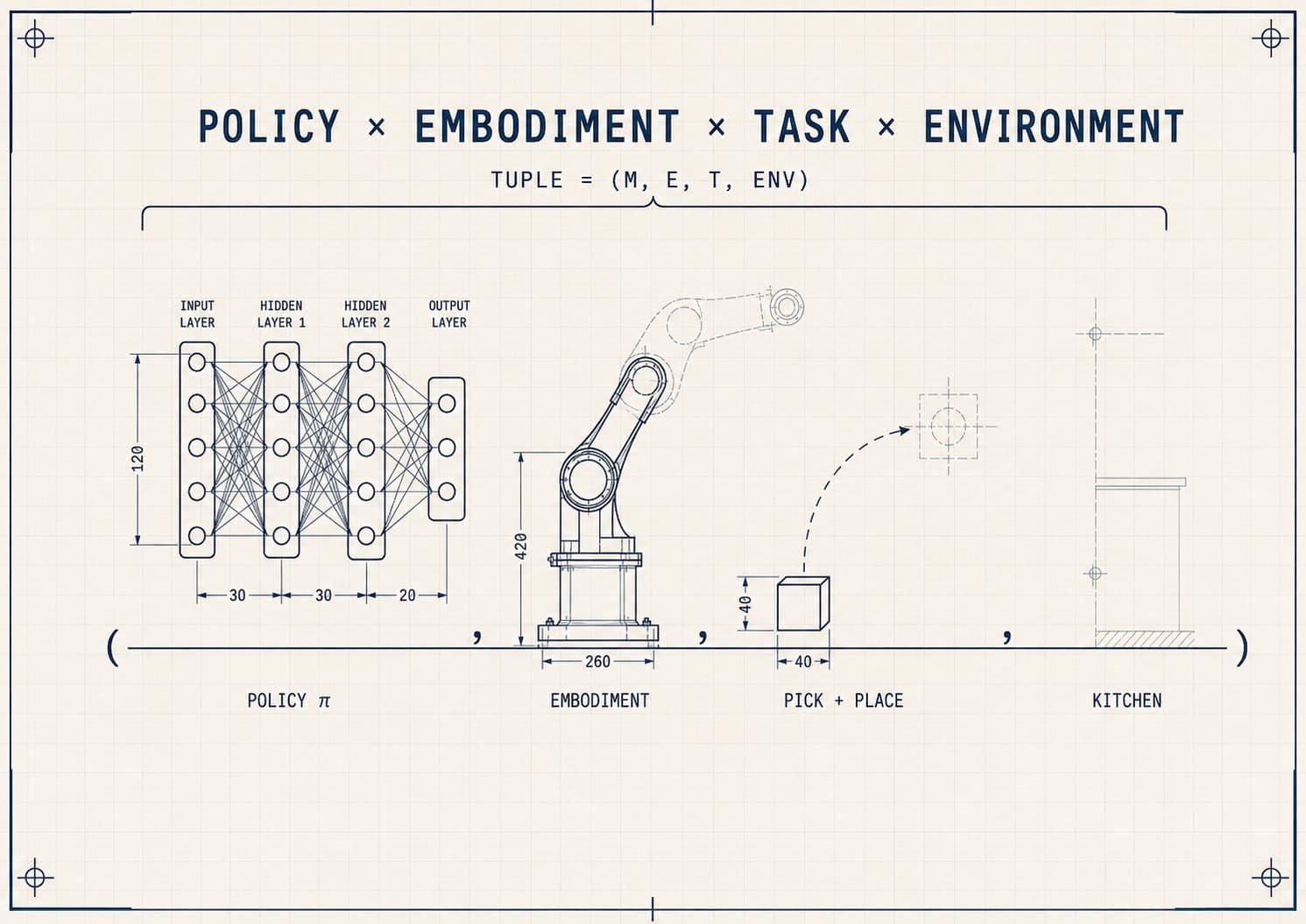
- The root cause is that the robotics problem domain is very sensitive to the combinatorial explosion of (which embodiment) × (which task) × (which policy) × (which environment).
- To be helpful, we lay out four open pain points and opportunities with an open call to builders. We think this is best handled as a community project, not a single company.
1. The Meme
If you spend any time in the physical AI space, a common meme is that there needs to be a “Hugging Face for robotics” or similarly a “GitHub for robotics”. Since we are sharing pain points and building in the open, we thought we would follow this rabbit hole and lay out for folks what problems are usually represented by this sentiment.
Quick aside: yes, Hugging Face already has a corner of its ecosystem dedicated to robotics. It is called LeRobot, and it is quite awesome. Policies, datasets, tools. Many researchers and builders use it. When people say “Hugging Face for robotics,” I am fairly certain they want to go further than LeRobot.
This post explains what we think it means and we invite builders to tackle the problems!
Additionally, we have collected choice quotes with similar sentiment and insights that helped us understand the underlying problems, which we cover in the next section.
- Chris Paxton put it bluntly: there's no “PyTorch for robotics,” and no HuggingFace Transformers either.
- Luis Fernandez, after building a sim sandbox from scratch, said he kept wishing for a “HuggingFace for robotics sim assets.”
- The team behind AIBot Hub wrote that there's no central hub where teams can browse, test, and contribute.
- Gabriele Tinelli and Kayoum Djedidi named the actual gap: code is only about 30% of what makes a robot work. The rest is hardware config, sim environment, model weights, calibration, and deployment tuning. What's missing, they argue, is the connective tissue.
- Kayoum also sketched what a fix would look like: a platform that versions not just code, but the full robot state.
Different people, different layers of the stack, same shape of complaint. That's the pattern we want to unpack.
2. So what does the “Hugging Face for robotics” meme actually mean?
Folks mean many different things when they say this. But when you read enough of these posts and talk to enough teams, a pattern emerges: an open community designed and tailored around a physical-AI-first taxonomy and workflow.
Some mean a model registry with robotics-specific metadata. Some mean a dataset hub that handles video-heavy robot data. Some mean simulation asset hosting. Some mean all of it at once. The phrase lives at many levels of the stack and different people feel the pain at different layers.
3. Why the open source playbook stalls here
GitHub and Hugging Face work because the thing they host travels well. A repo is code plus history, and code mostly runs the same on the next machine. A model is weights plus a tokenizer, and the model mostly behaves the same on the next GPU. You fork it, clone it, download it, and you get roughly what the original author had.
Robotics is not like that.
If LLM A beats LLM B at math on a Windows laptop, that result tells you something. Same model, different laptop, similar performance. The hardware is mostly invisible. The task is mostly self-contained.
Robot policies do not work that way. Policy A might beat Policy B on a Franka arm doing pick-and-place indoors, then lose badly on a UR5 doing the same task, then fail entirely outdoors. Change the embodiment, the task, or the environment and the result can flip.
The unit of value in robotics is not the model. It is the (model, embodiment, task, environment) tuple. Every pain below is a place where current tooling treats the model as the unit and loses the rest.
That is why a model card needs action space, control frequency, and which robot. That is why URDFs and MJCFs are load-bearing infrastructure, not config trivia. That is why dataset format conversions are dangerous: the embodiment is baked into the trajectories. That is why sim configs need to be portable. None of these are oversights. They are what happens when you try to apply LLM-shaped infrastructure to a problem that is not LLM-shaped.
4. Pains & Opportunities
1. You can't tell which models actually work with your robot
- Pain points:
- High-level: I have much more confidence in what I need to run (and what to expect!) when I download a Rust crate from GitHub or an LLM from Hugging Face. A VLA model may work really well in one environment and task but poorly in another.
- Concrete: A user fine-tuning SmolVLA for a Franka Panda hit 0% success despite clean training loss curves. Their issue is a list of questions the model card should have answered: what action space the model expects, what state representation, which camera names, and whether the SO100-pretrained checkpoint transfers to Franka at all.
- Opportunity:
- If I could wave a magic wand, we would collect open source data where robot model cards show how the model has actually performed, on which hardware, doing which tasks, in which environments. If a hundred people have run a pick-and-place on a UR5 in a kitchen, that should be part of the open data attached to the model. Real-world results, sim rollouts, all of it.
- You (or an AI agent) should be able to query: “Show me every model that runs on a 7-DOF arm at 30 Hz with reported success on pick-and-place.” Or: “Show me every policy that has done above average indoors with this humanoid embodiment.”
2. Robot descriptions are orphaned
Robot description files are how you tell a simulator what a robot is: its joints, links, masses, sensors. Several competing formats exist (URDF, MJCF, SDF, USD), and they do not play nicely together.
- Pain points:
- Why it's worse than it looks: Manufacturer specs are often incomplete, sometimes wrong, and rarely include the things that matter most for sim-to-real (inertia tensors, joint friction, motor models, contact parameters). The real ground truth gets discovered by the community: someone calibrates the dynamics, someone fixes a joint limit, someone measures the actual mass distribution. Today that hard-won knowledge lives in private forks and dies on people's laptops.
- Concrete: Want a UR5 URDF? You will find six versions, each slightly different, none telling you which is right. Pick the wrong one and your sim-trained policy fails on the real robot because the joint limits or inertial parameters did not match.
- Opportunity:
- If I could wave a magic wand, there would be one registry for robot descriptions. One place, multiple formats, with conversion between them and validation that the kinematics, dynamics, and collision geometry actually match the physical robot. Versioned, with the community keeping it up to date the way crates.io or npm stay current: anyone can submit fixes, updates, or measured corrections, and the registry tracks history.
- You (or an AI agent) should be able to ask: “Give me the canonical URDF for a UR5, with community-corrected dynamics.”
3. Simulation configs and runs are not treated as artifacts
A simulation is more than a 3D scene. It's the scene geometry, lighting, friction values, contact parameters, sensor noise, domain randomization, and reward functions. The whole bundle determines whether your sim-trained policy will work on the real robot.
- Pain points:
- High-level: Sim configs live inside repos as scattered YAML, Python, and asset files. Not portable, not versioned, not browsable. To reproduce someone's result you clone their repo, dig through
configs/, find the right file, and hope nothing else changed. - Why it's worse than it looks: Every team is re-running simulations that other teams already ran. There is no “I'll just grab that result from the hub.” We are burning GPUs to re-derive what the field already knows.
- Concrete: Your colleague trained a great pick-and-place policy in MuJoCo. Six months later, the friction values were tuned in a branch that got overwritten, the lighting came from an asset that was updated, and the randomization config references a file that no longer exists. You can rerun the script. You cannot rerun the experiment.
- High-level: Sim configs live inside repos as scattered YAML, Python, and asset files. Not portable, not versioned, not browsable. To reproduce someone's result you clone their repo, dig through
- Opportunity:
- If I could wave a magic wand, sim configs and the runs they produce would both be first-class artifacts. A config is a bundle: scene, randomization, reward, assets. A run is a config plus its trained policy, rollout videos, and success metrics. The community keeps it honest like crates.io or npm: anyone uploads, anyone forks, anyone flags a run that did not reproduce.
- The pains in this list are not independent. A sim run on a Franka doing pick-and-place is a model result, a robot test, and a dataset all at once. One platform, three flows of evidence: into the model card from pain #1, the robot description from pain #2, and the dataset record from pain #4.
- You (or an AI agent) should be able to ask: “Has anyone already run this scenario? Give me their results, save me the GPUs.”
4. Tested deployment configurations have no home
A real-world deployment is the tuple made concrete: this exact policy, running on this exact robot, doing this exact task, in this exact environment. It's the bundle that has been debugged, tuned, and proven to actually work on the floor: the trained model, the URDF, the calibration, the safety limits, the deployment runtime, the demos used to fine-tune. The set of all such bundles is the operating knowledge of the field.
- Pain points:
- High-level: Most of these working bundles are kept internally at labs and companies. Someone got a Franka doing pick-and-place to work in a kitchen and tuned a hundred small things to get there. That work exists. It just lives in their fork, their VM, their head. The next person doing nearly the same thing has to redo most of it.
- Why it's worse than it looks: It is not as simple as just uploading them to GitHub (which folks do). We need a native form factor that embraces and accounts for the combinatorial explosion of policies × embodiments × tasks.
- Concrete:
- Imagine someone has uploaded a tested bundle: a pick-and-place policy on a Franka arm, in a kitchen, with a specific gripper. Everything in the bundle is proven and battle-tested by the community: the URDF, the camera calibration, the safety limits, the demos used to fine-tune. You drop it onto a matching setup and it just works.
- Now a new version of the policy comes out. You want to use it on the same arm, same task, same kitchen. You spend a few hours adjusting the bundle: tweaking calibration, retuning safety limits, redoing a few demos. It works. You have a new tested bundle for the new policy version. You want to be able to upload the new version for this new tuple of same embodiment × same task × new policy version.
- Opportunity:
- If I could wave a magic wand, tested deployment bundles would be a first-class artifact that was open source, versioned, tested across embodiments × policies × tasks. The platform would embrace variant explosion. Bundles would be versioned, browsable, and rated.
- If five people have published bundles for the same policy on the same arm, you should be able to see which one has the most stars, which one was last tested, and which one has working forks for adjacent grippers or tasks.
- The same way GitHub uses stars and Yelp uses ratings, this platform needs community signal so people can tell which bundles are reliable and which are stale.
- You should be able to ask: “Find me the highest-rated bundle for this policy on this arm with this gripper, and if none exist, show me the closest match.”
- If I could wave a magic wand, tested deployment bundles would be a first-class artifact that was open source, versioned, tested across embodiments × policies × tasks. The platform would embrace variant explosion. Bundles would be versioned, browsable, and rated.
These patterns keep showing up because they are structural. They will not be solved by bolting features onto a platform that was built for language models.
5. An Open Call
A pattern we keep running into: people ask us where the opportunities are. Founders, researchers, engineers thinking about jumping into Physical AI. Well, the four pains above are our honest answer. Each one is a real opening and we want to see what folks come up with! We have a suspicion this is best handled as an open community project more than a single stand-alone company.
So this post is an open call!
- To entrepreneurs: four concrete openings, all not-quite-solved as of yet.
- To people who already feel this: we want to find you. If any of this resonates, get in touch. If you think this is nonsense, we want to hear it too! We are not trying to own the answer; we want to race towards truth.
- To everyone: of course we threw AI at this. You should too. Drop this post into Claude, Cursor, whatever you use, and run with it. Sketch the schema. Mock the registry. Build a prototype over a weekend. The bar to start is lower than ever, and the field needs more swings.
We will open source some of the things we have been experimenting with. The point is not our experiments. One such experiment is Festivus. We just wrote about it.
The main point of this post is to see what other people come up with, and to share what works.
Got an idea? Hit us up on X or reach out. We would love to share it!
Haptic is building tools and infrastructure for physical AI research teams. If you are working on physical AI and want to talk, reach out.